伙伴匹配系统

伙伴匹配系统
Abei伙伴匹配系统
介绍:帮助用户找到志同道合的伙伴
需求分析
- 用户去添加标签,标签的分类(要哪些标签,怎么把标签进行分类)学习方向?
- 主动搜索:允许用户根据标签去搜索其他用户
- Redis 缓存
- 组队
- 创建队伍
- 加入队伍
- 根据标签查询队伍
- 邀请其他人
- 允许用户去修改标签
- 推荐
- 相似度计算算法 + 本地分布式计算
技术栈
前端
- Vue 3 开发框架(提交页面开发效率)
- Vant UI (基于 Vue 的移动端组件库) (React 版 Zent)
- Vite (打包工具,快!)
- Nginx 来单机部署
后端
- Java 编程语言 + SpringBoot 框架
- SpringMVC + Mybatis + Mybatis Plus
- MySQL 数据库
- Redis 缓存
- Swagger + Knife4j 接口文档
第一期
- 前端初始化
- 前端主页 + 组件概览
- 数据库表设计
- 标签表
- 用户表
- 开发后端 - 根据标签搜索用户
- 开发前端 - 根据标签搜索用户
前端项目初始化
用脚手架初始化项目
- Vue CLI
- Vite 脚手架
整合组件库 Vant:
- 安装 Vant
- 按需引入 指令参考官方文档
开发页面经验:
- 多参考
- 从整体到局部
- 先想清楚页面要做成什么样子,再写代码
前端主页 + 组件概览
设计
- 导航条:展示当前页面
- 主页搜索框 -> 推荐页 -> 搜索结果页
- 内容
- tab栏:
- 主页(推荐页 + 广告)
- 搜索框
- banner
- 推荐信息流
- 队伍页
- 用户页
- 主页(推荐页 + 广告)
开发
很多页面要复用组件 / 样式,重复写很麻烦,不利于维护,所以抽象一个通用的布局(Layout)
数据库表设计
标签的分类(要有哪些标签,怎么把标签分类)
标签表(分类表)
建议用标签不要用分类。更灵活
- 性别 : 男,女
- 方向:Java、Python、C++
- 目标:考研、春招、秋招、考公、竞赛
- 身份:大学生、待业、研究生
- 状态:乐观、有点丧、一般、单身、已婚、有对象
- 【用户自定义标签】?
字段:
id int 主键
标签名 varchar 非空 (必须唯一,唯一索引)
userId 上传标签的用户 int (普通索引)
parentId 父标签 int(分类)
isParent 是否为父标签 tinyint
creatTime 创建时间 datetime
updateTime 更新时间 datetime
isDelete 是否删除 tinyint
怎么查询所有标签,并且把标签分好组?能实现 √
根据父标签查询子标签,根据id查询 √
SQL语言分类:
DDL define 建表、操作表
DML manager 更新删除数据,影响实际表里的内容
DCL control 控制、权限
DQL query 查询
用户表
用户有哪些标签?
- 直接在用户表补充 tags 字段,[‘java’, ‘男’]存 JSON 字符串
- 优点:查询方便,不用新建关联表,标签是用户的固有属性(除了该系统、其他系统可能也要使用),节省开发成本。
- 缺点:用户表多一列,会有点
- 哪怕性能低,可以用缓存
- 加一个关联表,记录用户和标签的关系
- 优点:查询灵活,可以正查反查
- 缺点:要多建一个表、多维护一个表
- 重点:企业大项目开发中尽量减少关联查询,很影响扩展性,而且会影响查询性能
开发后端接口
搜索标签:
- 允许用户传入多个标签,多个标签都存在才搜索出来 and。like %Java% and like %C++%
- 允许用户传入多个标签,有任何一个标签存在就能搜索出来 or。like %Java% or like %C++%
两种方式:
- SQL查询
- 内存查询
用户中心来集中提供用户的检索、操作、登录、鉴权等等
第二期
- 前端开发(搜索页面、用户信息页、用户信息修改页)
- 前端整合路由
- 后端整合Swagger + Knife4j 接口文档
- 存量用户信息导入及同步(爬虫)
Java 8
- stream / parallelStream 流式处理
- Optional 可选类
前端整合路由
点击去Vue-Router 官方文档 ->>> Vue-Router
Vue - Router 其实就是帮助你根据不同的 url 来展示不同的页面(组件),不用自己写 if / else
路由配置影响整个项目,所以建议单独用 config 目录、单独的配置文件去集中定义和管理。
有些组件库可能自带了和 Vue-Router 的整合,所以尽量先看组件文档,省去自己写的时间。
第三期
计划:
- 后端整合Swagger + Knife4j 接口文档
- 存量用户信息导入及同步(爬虫)
- 前后端联调:搜索页面、用户信息页、用户信息修改页
- 标签整理、部分细节优化
后端整合Swagger + Knife4j 接口文档
什么是接口文档?写接口信息的文档,每条接口包括:
- 请求参数
- 响应参数
- 错误码
- 接口地址
- 接口名称
- 请求类型
- 请求格式
- 备注
谁用?一般是后端或者负责人提供,后端前端都要使用
为什么需要接口文档?
- 有个书面内容(背书或者归档),便于大家参考和查阅,便于沉淀和维护,拒绝口口相传
- 有个文档方便与前端和后端开发对接,前端后端联调的==介质==。后端=>接口文档<=前端
- 好的接口文档支持在线调试、在线测试,可以作为工具提高我们的开发测试效率
怎么做接口文档?
- 手写(比如腾讯文档、Markdown笔记)
- 自动化接口文档生成:Swagger、Postman(侧重接口管理);apifox,apipost,eolink(国产)
Swagger原理:
- 自定义 Swagger 配置类
- 定义需要生成接口文档的代码位置(Controller)
千万注意:线上环境不要把接口暴露出去
[!NOTE]
可直接引入knife4j,其集成了 Swagger 和 openAPI ==引入请见官方文档==。
FeHelper 前端插件 推荐安装
第四期
计划:
- 页面和功能开发(搜索页面、用户信息、用户修改页面)
- 改造用户中心,把单机登录改为分布式 session 登录
- 标签的整理、细节的优化
前端页面跳转传值
- query => url searchParams, url 后附加参数(传递值长度有限)
- vuex (全局状态管理),搜索页将关键词塞到状态中,搜索结果页从状态中取值
以下代码使用参考Vue Router官方文档 ->>> Vue Router
1 | // 字符串路径 |
整合Axios
点击去官方文档 ->>> Axios中文文档
Session 共享
Cookie 范围
种 session 的时候注意范围, Springboot 项目中可以通过 cookie。domain 来配置。(3.0版本之后不需要配置)
比如两个域名:
- aaa.abeibiiji.com
- bbb.abeibiji.com
如果要共享cookie ,可以种一个更高层的公共域名,比如 abeibiji.com
为什么需要共享?
思考:为什么服务器A登录后, 请求发送到服务器B,不认识该用户?
原因:
- 用户在A登录,所以 session (用户登录信息)存在了 A 上
- 结果请求 B 时,B 没有用户信息,所以不认识。
如图:

解决方案:==共享存储==,而不是把数据放到单台服务器的内存中

如何共享存储
核心思想:把数据放到同一个地方去管理
- Redis(基于内存的 K/V 数据库)此处选择 Redis,因为用户信息读取 / 是否登录的判断极其 ==频繁==,Redis 基于内存,读写性能很高,简单的数据单机 qps 5w - 10w
- MySQL
- 文件服务器 ceph
Session 共享实现
安装 Redis
安装 Redis 管理工具 quick redis
引入 Redis:
1 | <dependency> |
- 引入 spring-session 和 redis 的整合,使得自动将session 存储到 redis 中。
其他单点登陆方案
常用的就是 JWT
Redis Session 对比 JWT 的优缺点 基于jwt和session的区别和优缺点
开发主页
直接使用的 card 组件列表展示。
模拟 100万用户数据查询。
100 万用户数据插入方式
- 用编译器的可视化界面导入:适合一次性导入,数据量可控
- 编写程序:for 循环,建议分批,不要一把梭哈(可以用接口来控制)。==要保证可控,幂等,注意线上环境和测试环境是有区别的!==
- 执行 SQL 语句:适用于小数据量
编写一次性任务
1 | // 使用 for 循环遍历插入数据 |
Redis
定义 :
NoSQL 数据库
key - value 存储系统(区别于 MySQL,他存储的是键值对)
String 字符串类型:name:“kele”
List 列表:names:[“kele”,”abei”,”abei”]
Set 集合:names:[“kele”,”abei”] (值不能重复)
Hash 哈希:nameAge:{“kele”:1,”abei”:2} (键不能重复)
Zset 集合:names:{kele - 9, abei - 12} (每个值都要指定一个分数。适合做排行榜)
bloomfilter(布隆过滤器,主要从大量的数据中快速过滤值,比如拦截邮件黑名单)
geo (计算地理位置)
hyperloglog (pv / uv)
pub / sub (发布订阅,类似消息队列)
BitMap (10101010010100011110101)
通用的数据访问框架,定义了一组增删改查的接口。
引入
1 | 引入版本需于Spring Boot 的版本一致 |
配置 Redis 地址
1 | spring: |
Jedis
独立于 Spring 操作 Redis 的 Java 客户端
要配合 Jedis Pool 使用
Redisson
分布式操作 Redis 的 Java 客户端,让你像在使用本地集合一样操作 Redis (分布式 Redis 数据网格)
Lettuce
高阶的操作 Redis 的 Java 客户端
对比:
- 如果你用的是 Spring ,并且没有过多的定制化要求,可以用Spring Data Redis,最方便
- 如果你用的不是Spring ,并且追求简单,并且没有过高的性能要求,可以用 Jedis + Jedis Pool
- 如果你的项目不是 Spring,并且追求高性能、高定制化,可以用 Lettuce。支持异步、连接池
- 如果你的项目是分布式的,需要用到一些分布式的特性(比如,分布式锁、分布式集合),推荐用 redisson
缓存
数据库慢?预先把数据查出来,放到一个更快读取的地方,不用再查数据库了。(缓存)
- 提前把数据取出来保存好(通常保存到读写更快的介质,比如内存),就可以更快的读写。
防止第一个用户的数据加载是从数据库中取出,从而导致第一个用户或者前几个用户的体验较差。
- 预加载缓存,定时更新缓存。(定时任务)
多个机器都要执行任务么?
缓存实现方式
- Redis (分布式缓存)
- memcached (分布式)
- Etcd(云原生架构的一个分布式存储,存储配置,扩容能力强)
- ehcache(单机)
- 本地缓存(Java 内存 Map )
- Caffeine(Java 内存缓存,高性能)
- Google Guava
设计缓存Key
不同用户看到的数据不同
systemId.moduleId.func< options > (不要和别人冲突)
redBirds:user:recommend:userId
redis内存不能无限增加,一定要设置过期时间!!!
为什么要设置过期时间?
缓存预热
问题:第一个用户访问很慢,怎么优化?
缓存预热的优缺点:
- 解决第一个用户访问慢的问题
缺点:
- 增加开发成本(额外开发、设计)
- 预热的时机和时间如果错了,有可能你缓存的数据不对或者太老
- 需要占用额外空间
分析优缺点的时候,要打开思路,从整个项目从 0 到 1 的链路上去分析
注意点:
- 缓存预热的意义(新增少,总用户多)
- 缓存的空间不能太大,要预留给其他缓存空间
- 缓存数据的周期
怎么缓存预热?
- 定时
- 模拟触发(手动触发)
定时任务实现
- Spring Scheduler (spring boot 默认整合了)
- Quartz (独立于 Spring 存在的定时任务框架)
- XXL - Job 之类的分布式任务调度平台(界面 + sdk)
用定时任务,每天刷新所有用户的推荐列表。
第一种方式实现:
- 主类开启 @EnableScheduling
- 给要定时执行的方法添加 @Scheduling 注解,指定 cron 表达式或者执行频率
将推荐改为缓存实现
1 |
|
缓存处理前后对比
目前首页数据加载时间:

添加缓存后的加载时间:
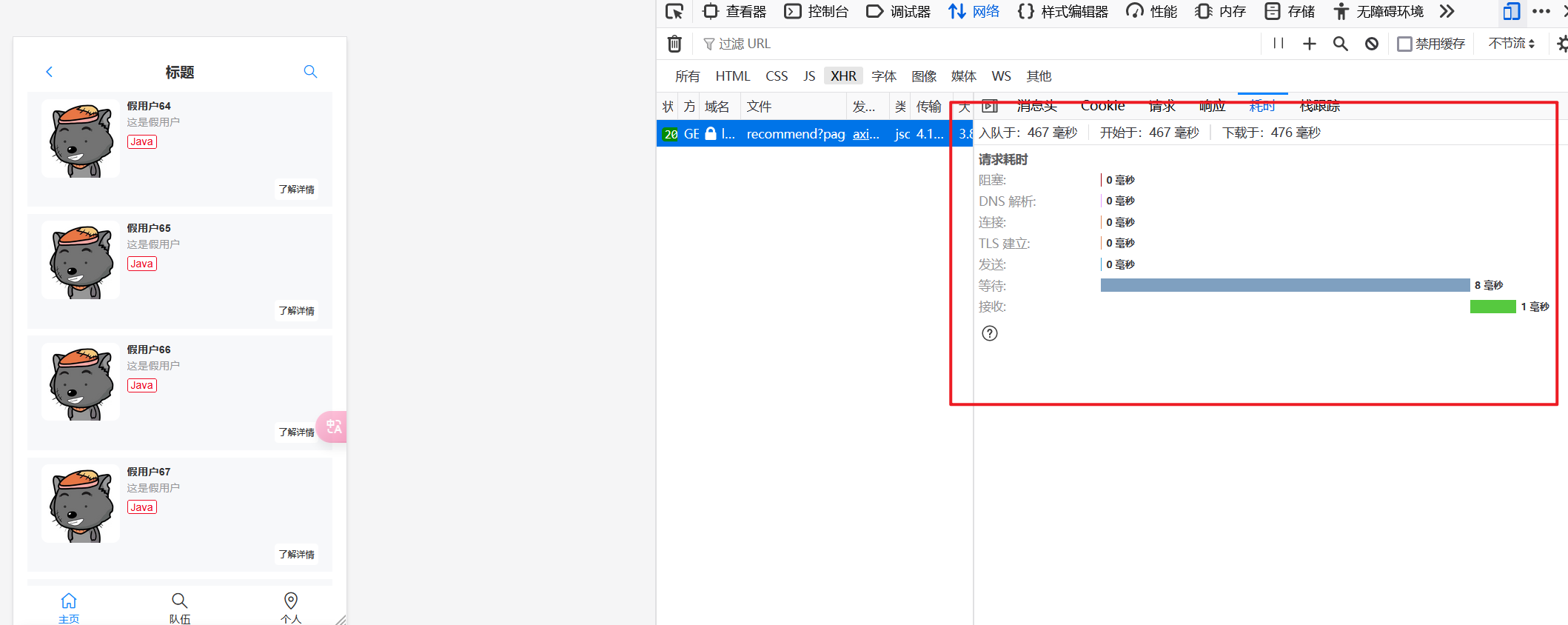
控制定时任务的执行
为什么?
- 浪费资源,想象10000台服务器同时执行?
- 脏数据,比如重复插入
要控制定时任务在同一时间只有一个服务器能执行。
怎么做?
- 分离定时任务和主程序,只在一个服务器运行定时任务。成本太大
- 写死配置,每个服务器都执行定时任务,只有指定ip的服务器才真实执行业务逻辑,其他的字节返回。if判断
上诉方式还可能存在什么问题?
- 动态配置,配置是可以轻松的、很方便的更新的(代码无需重启),但是只有 IP 符合配置的服务器才真实执行业务逻辑。
- 数据库
- Redis
- 配置中心(Nacos、Apollo、Spring Cloud Config)
上诉方式还存在什么问题吗?
- 分布式锁,只有抢到锁的服务器才能执行业务逻辑。坏处:增加成本;好处:不用手动配置,多少个服务器都一样。
引出新技术: 锁
锁
1 | // 如果创建10个线程执行以下代码 |
jvm锁和分布式锁有什么区别
jvm锁指的是 Java 中的 ynchronized 关键字。加在函数前面表示只能同时被一个线程执行。但是此锁只能管同一个JVM中的程序,无法处理多个服务器部署的情况。
Java 实现锁:ynchronized 关键字,并发包的类
为什么需要分布式锁?
- 有限资源的情况下,控制同一时间段只有某些线程(用户/服务器)能访问到资源。
- 单个锁只对单个 JVM 有效。
分布式锁的实现关键
抢锁机制:
- 怎么保证同一时间只有一个服务器能够抢到锁?
核心思想:先来的人先把数据改成自己的标识(服务器ip),后来的人发现标识已存在,就抢锁失败,继续等待。
等先来的人执行方法结束,把标识清空,其他的人继续抢锁。
实现方式
MySQL 数据库:select for update 行级锁(最简单)
(乐观锁)
※Redis 实现:内存数据库,读写速度快。支持setnx、lua 脚本,比较方便我们实现分布式锁。
- setnx:set if not exist 如果不存在,则设置;只有设置成功才会返回true,否则false
Zookeeper 实现(不推荐)
注意事项
- 用完锁要释放
- 锁一定要加过期时间
- 如果方法执行时间过长,锁提前过期了?
- 这样还是会存在多个方法同时执行的情况
- 连锁效应:释放掉别人的锁。(锁设置30秒,A程序执行40秒,30秒之后,B拿到锁执行程序,B程序需要执行20秒,但是A 在执行完成之后释放了B的锁)
- 解决方法:释放锁的时候检查标识是不是自己的。
- 解决方法:续期
- A释放锁的时候,需要进行锁是不是自己的判断。如果此时判断的时候锁是自己的,但是进入删除逻辑的瞬间锁过期了,B发现空着,进来拿到锁,然后A执行释放逻辑,依然释放掉了B的锁。
- 解决方式:在A判断锁的整个逻辑中,不允许任何程序插入。采用原子操作。Redis + lua 脚本实现
定时任务 + 锁
- waitTime 设置为0,只抢一次,抢不到就放弃
- 注意释放锁要写在 finally 中(万一前面报错锁也得释放)
看门狗机制
redisson 的续期机制
开一个监听线程,如果方法还没执行完,则续期
原理:
- 监听当前线程,每10秒续期一次
- 如果线程挂掉(注意 debug 模式也会被认为是服务器宕机),则不会续期
看门狗机制详解 ->>> Redisson 分布式锁的watch dog自动续期机制
Redis 如果是集群(而不是只有一个 Redis ),如果分布式锁的数据不同步怎么办?
- 红锁(Redlock) ->>> Redisson–红锁(Redlock)–使用/原理
Redisson 实现分布式锁
Java 客户端,数据网格
实现了很多Java里支持的接口和数据结构
Redisson 是一个 java 操作 Redis 的客户端,提供了大量的分布式数据集来简化对 Redis 的操作和使用,可以让开发者像使用本地集合一样使用 Redis,完全感知不到 Redis 的存在。
两种引入方式:
- spring boot starter 引入(不推荐,版本迭代太快,容易冲突)
- github链接 ->>> redisson-spring-boot-starter
- ※直接引入
访问 redisson 的 github 仓库,点击 Quick Start
使用 maven 导入包

往下翻就有 Java 的快速实现。
编写 RedissonConfig 文件
1 |
|
组队功能
需求分析
用户可以创建一个队伍,设置队伍的人数、队伍名称(标题)、秒速、超时时间
- 队长、剩余的人数
- 聊天?
- 用户可以加入队伍(其他、未满、未过期)
- 邀请
- 是否需要队长同意?
- 用户可以退伍(如果队长推出,权限转移给第二早加入的用户 —— 先来后到)
- 队长可以解散队伍
- 分享队伍 => 邀请其他用户加入队伍
- 公开或者加密
- 修改队伍信息
- 不展示已过期的队伍
- 可以加入多个队伍,但是要有上限
- 队伍人满后发送消息通知
- 用户创建队伍的上限多少
展示队伍列表,根据名称搜索队伍,信息流中不展示已过期的队伍。
系统(接口)设计
- 请求参数是否为空?
- 是否登录,未登录不允许创建
- 校验信息
- 队伍人数 >1 且 <=20
- 队伍标题 <= 20
- 描述 <= 512
- teamStatus 是否公开(int)不传默认为 0 (公开)
- 密码有的话 <= 32
- 超时时间 > 当前时间
- 校验用户最多创建5个队伍
- 插入队伍信息到队伍表
- 插入用户 => 队伍关系到关系表
数据库表设计
队伍表 team
字段:
- id 主键 bigint (最简单、连续,放 url 上比较简短,但缺点是爬虫)
- name 队伍名称
- description 描述
- maxNum 最大人数
- expireTime 过期时间
- userId 用户 id
- status 0 - 公开, 1 - 私有 , 2 - 加密
- teamPassword 密码
- createTime 创建时间
- updateTime 更新时间
- isDelete 是否删除
1 | create table team |
两个关系:
- 用户加了哪些队伍?
- 队伍里有哪些用户?
方式:
- 建立用户 - 队伍关系表 teamId userId(便于修改,查询性能高一点,可以选择这个,不用全表遍历)
- 用户表补充已加入的队伍字段,队伍表补充已加入的用户字段(不用写多对多的代码,可以直接根据队伍查用户、根据用户查队伍)
用户 - 队伍表
user_team
字段:
- id 主键
- userId 用户 id
- teamid 队伍 id
- joinTime 加入时间
- createTime 创建时间
- updateTime 更新时间
- isDelete 是否删除
1 | create table user_team |
为什么需要请求参数包装类?
- 请求参数名称和实体类不一样
- 有一些参数用不到,如果要自动生成接口文档,会增加理解成本
为什么需要包装类?
可能有些字段需要隐藏,不能返回给前端
或者有些字段某些方法是不关心的
开启事务
1 | // 开启事物 |
为了保证队伍表和用户队伍表的数据一致。防止队伍表插入成功而队伍用户表插入失败的情况。如果出现异常,事物自动回滚。
查询队伍列表
展示队伍列表,根据名称搜索队伍,信息流中不展示已过期的队伍。
- 从请求参数中取出队伍名称,如果存在则作为查询条件
- 不展示已过期的队伍(根据过期时间筛选)
- 关联查询已加入队伍的用户信息
- 只有管理员才能查看加密的房间









